
Mfalme S5G

All-in-one Box Prevails over AI and HPC challenge NVIDIA® NGC Ready Server Up to 8x NVIDIA® Tesla® V100 with NVLink™ support up to 300GB/s GPU to GPU communication Up to 10x dual-width 300 Watt GPU or 16x single-width 75 Watt GPU support Diversify GPU topology to Conquer Any Type of Parallel Computing Workload Up to 4x100Gb/s High Bandwidth RDMA-enabled Network to Scale Out with Efficiency 8x NVMe Storage to Accelerate Deep Learning
Description
Mfalme S5G
Need to do 560 Teraflops in a Single Rack..?
The D52G-4U also known as D5G is the world’s fastest GPU server. Hyperconverged: 8 * NVMe with up to 16 * GP-GPU the D5G does 56 Double Precision Teraflops in 4U. It is ideal for: Big Data, Deep learning, Artificial Intelligence and Inferencing. D52G boasts: NVLink™ support up to 300GB/s GPU to GPU communication | 10x dual-width 300 Watt GPU | 16x single-width 75 Watt GPU support | Diversify GPU topology to Conquer Any Type of Parallel Computing Workload | Up to 4x100Gb/s High Bandwidth RDMA-enabled Network to Scale Out with Efficiency | 8x NVMe Storage to Accelerate Deep Learning.
 |
 |
Deep learning with up to 16 GPU featuring with NvlinkTM
With NVLinkTM to support up to 300GB/s GPU to GPU communication, D52G-4U can shorten model-training time-frame, which is 40x faster than conventional server on processing 408GB Chest X-ray images.
 |
 |
10x dual-width 300 watt GPU or 16x single-width 75 Watt GPU support
As an purpose-built system for Artificial Intelligent (AI) and High-Performance Computing(HPC) workloads, QuantaGrid D52G-4U can deliver up to 896 tensor Tflops to training deep learning model with eight* NVIDIA® Tesla V100 dual-width 10.5 inch or provides up to 293 GOPS/watt of peak INT8 performance to do inferencing with sixteen NVIDIA® Tesla P4 and 2-socket Intel® Xeon® Scalable processor; up to 56 double precision Tflops computing power can accelerate HPC workloads such as Oil & Gas, bioinformatics, Mechanical Engineering. On top of superior computing power, D52G is of 2x100Gb/s high bandwidth low-latency networking to expedite communication among different GPU nodes
 |
 |
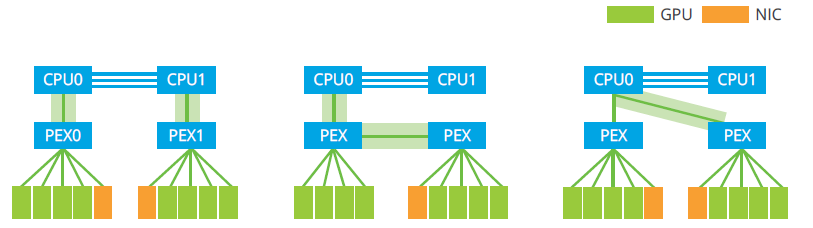
Diversify GPU Topology to Conquer Any Type of Parallel Computing Workload
The QuantaGrid D52G provides multiple GPU topology on the same baseboard tray to meeting your different use case.
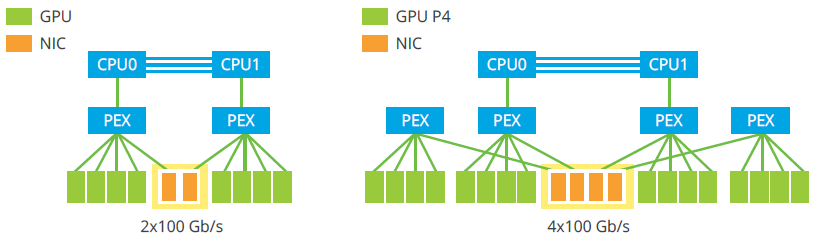
High-Bandwidth, Low-latency Networking Between GPU Nodes
The QuantaGrid D52G-4U have additional two/four PCIe Gen3x16 LP-MD2 slot to provide optional two/four 100Gb/s low-latency infiniband or Intel®Omni Path options to do GPUDirect in the server or RDMA between different GPU nodes.
NVMe SSD Support to Accelerate Deep Learning
The D52G-4U support max. 8x NVMe SSD, which can accelerate both training and inferencing with Fast I/O data reading as deep learning is a data-driven algorithm.




